Managed Big-Data Stack
Gestern und heute
Aus den Erfahrungen vieler Big-Data Projekte hat sich über die Jahre unser Big-Data-Stack entwickelt.
Noch vor wenigen Jahren gab es keine wirkliche Alternative zum klassischen Hadoop-Ökosystem aus MapReduce, YARN, HDFS usw. Doch seither hat sich vieles geändert:
Apache Spark ist der de-facto Standard für die verteilte Verarbeitung großer Datenmengen geworden und hat Maßstäbe in Sachen Performance gesetzt. An Kubernetes zum Planen und Ausführen von Workloads führt kein Weg mehr vorbei. S3 kompatible Objekt-Speicher sind in Sachen Haltbarkeit und Kosten an HDFS Dateisystemen vorbeigezogen.
Und auch wir haben unsere Set-ups immer wieder verändert. Wo vorher komplexe Hadoop-Distributionen mit Vendor lock-in aufgesetzt waren, stehen jetzt schlanke, verständliche, Open-Source basierte Installationen auf Basis von Kubernetes.
Gute Werkzeuge
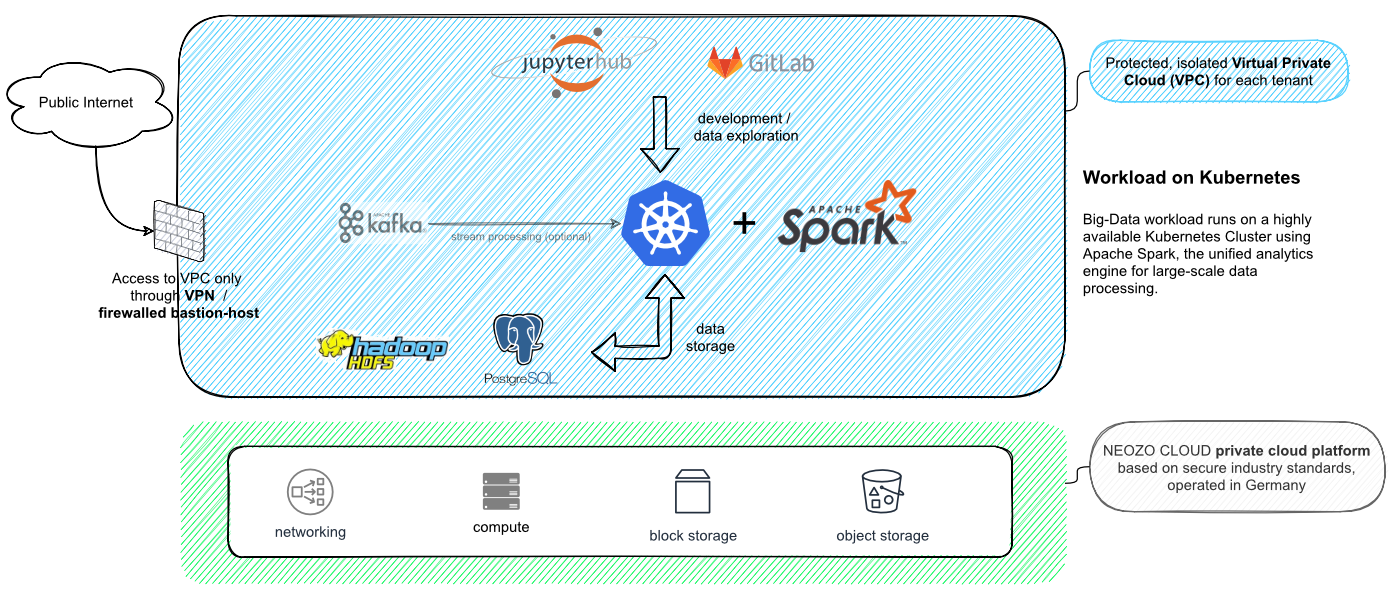
Aus Kundenprojekten hat sich im Laufe der Jahre für den Stack ein Standard-Set von Werkzeugen herauskristallisiert:
Mit Jupyter-Hub arbeiten Ihre Datenwissenschaftler interaktiv, um Erkenntnisse aus strukturierten und unstrukturierten Daten zu gewinnen. Die im Rahmen der interaktiven Arbeit mit den Daten entstehenden Programme werden dann im GitOps-Verfahren betrieben. Dazu verwenden wir das Tool Gitlab.
Sämtliche Arbeitslasten werden auf einem für Sie exklusiven, hochverfügbaren Kubernetes-Cluster ausgeführt. Optional stehen Ihnen für KI-Workloads GPU-Beschleuniger zur Verfügung. Unsere aussagekräftigen Dashboards erlauben tiefe Einblicke in die Auslastung des Clusters.
Für die Speicherung von Daten können Sie nach Bedarf S3 kompatiblen Object-Speicher, HDFS, diverse Datenbanken (MariaDB, Postgres) oder Apache Kafka (für Streaming-Daten) nutzen - auch in beliebigen Kombinationen.
Der Stack kann natürlich individuell erweitert werden. Als Beispiel betreiben wir für einige Kunden als Zusatz das lizenzpflichtige Business-Intelligence Produkt Tableau.